JPA의 EntityManager와 새로운 엔티티를 구분하는 방식

JPA에서 가장 중요한 핵심은 영속성 컨텍스트이다.
위 질문에 답을 하기 위해선 영속성 컨텍스트에 대한 이해가 필요하다.
영속성 컨텍스트
엔티티 객체를 1차 캐시 형태로 보관하고 관리하는 JPA의 논리적 개념
즉, DB와 애플리케이션 사이에서 엔티티를 캐싱하고 상태를 추적하는 중간 관리자 역할을 한다고 이해하면 된다.
이러한 영속 객체에 대한 관리는 EntityManger의 메서드를 이용해 수행된다.
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
Optional<Member> findByName(String name);
}
JPA를 활용하기 위해 Repository를 작성하면 해당 인터페이스를 스프링이 프록시 객체로 구현 클래스(SimpleJpaRepository)를 만들어 준다.
public class SimpleJpaRepository<T, ID> implements JpaRepository<T, ID> {
private final EntityManager em;
public SimpleJpaRepository(EntityManager em) {
this.em = em;
}
@Override
public Optional<T> findById(ID id) {
return Optional.ofNullable(em.find(domainClass, id));
}
}
EntityManger를 주입받고 있는 것을 확인할 수 있다.
엔티티 생명 주기
![[Pasted image 20250918110437.png]]
엔티티에는 총 4가지 상태가 존재한다.
비영속
엔티티 객체를 단순히 생성한 상태이며 영속성 컨텍스트와 아무 관련이 없는 상태이다.
Member member = new Member();
member.setId(1L);
member.setName("회원1");
영속
엔티티 매니저를 통해 엔티티를 영속성 컨텍스트에 저장하거나,
DB로 부터 조회했을 때 영속성 컨텍스트가 엔티티를 관리하게 된다.
즉, 영속성 컨텍스트가 관리하는 엔티티를 영속 상태라고 한다.
em.persist(member);// entity를 영속성 컨텍스트에 저장(영속 상태로 만듬)
em.find(Member.class, id);
준영속
영속 상태의 엔티티가 영속성 컨텍스트에서 분리된 상태
영속성 컨텍스트가 제공하는 기능을 사용하지 못함
em.detach(member); // 회원 엔티티를 영속성 컨텍스트에서 분리
em.clear(); // 영속성 컨텍스트 초기화
em.close(); // 엔티티 매니저(영속성 컨텍스트) 종료
@Transactional 스코프에서 벗어난 순간 준영속 상태가 되어 추가적인 기능을 사용하지 못하게 된다.
삭제
엔티티를 삭제 대상으로 표시한 상태이다.
커밋 시 DB에서 삭제가 수행된다.
em.remove(member);
영속성 컨텍스트의 특징
엔티티들을 DB에 바로 반영하지 않고 굳이 영속성 컨텍스트라는 공간에서 관리하는 이유는 무엇일까?
1차 캐시
영속성 컨텍스트는 내부에 엔티티를 저장할 수 있는 캐시를 가지고 있고 이를 1차 캐시라고 부른다.
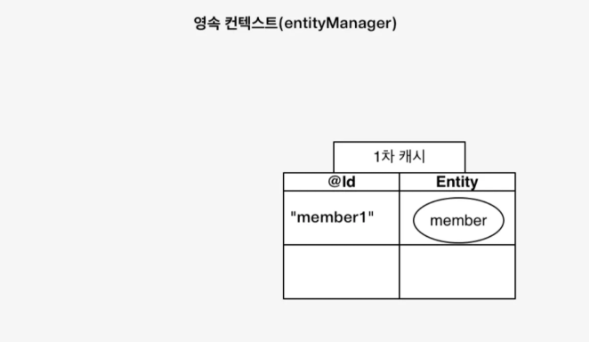
조회하려는 엔티티가 1차 캐시에 존재한다면 DB에 접근하지 않고도 메모리 상에서 조회할 수 있는 이점을 가진다.
만약 1차 캐시에 존재하지 않는다면 DB에서 조회 후 영속 상태로 만들어 관리한다.
동일성 보장
영속성 컨텍스트에서 관리되는 엔티티를 비교할 때, @Id 값이 같다면 동일한 엔티티 인스턴스를 반환한다.
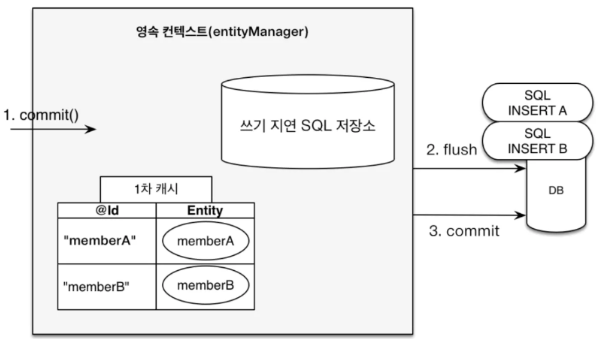
쓰기 지연
commit() 이 호출되기 전까지 내부 쿼리 저장소에 실행될 SQL을 모아 한번에 호출한다.
변경 감지
엔티티를 수정할 때 update()와 같은 메서드가 필요없다.
JPA는 엔티티를 영속성 컨텍스트에 보관할 때, 최초 상태의 스냅샷을 저장하여 flush()가 호출되는 시점에 스냅샷과 엔티티를 비교해서 변경된 엔티티를 찾아 변경 쿼리를 생성해준다.
플러시 flush()
플러시는 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영하는 기능이다.
즉, 영속성 컨텍스트를 DB와 동기화 하는 작업이라 생각하면 된다.
플러시가 실행되면 아래와 같은 과정이 일어난다.
- 변경 감지가 동작하며 스냅샷과 비교
- 수정된 엔티티가 있다면 수정 쿼리를 만들어 쓰기 지연 저장소 등록
- commit()이 호출되면, 쓰기 지연 SQL 저장소의 모든 쿼리가 DB에 전송된다.
추가로 flush를 한다고 해서 1차 캐시가 지워지는 것은 아니다.
플러시는 호출하는 방법은 3가지가 있다.
- 직접 호출
- commit()시 자동 호출
- JPQL 쿼리 실행 시 자동 호출
JPA는 어떻게 save() 호출 시 update, insert를 구분할 수 있을까?
save() 메서드의 내부 구현을 확인해보자
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (entityInformation.isNew(entity)) {
entityManager.persist(entity); // INSERT
return entity;
} else {
return entityManager.merge(entity); // UPDATE
}
}
entitiyInformation.isNew(entity) 를 통해 새로운 객체라면 insert 쿼리가 나가게끔 동작하고 있다.
entityInformation 구현체는 여러가지가 존재한다.
엔티티 클래스
│
├─ @Version 존재? ── Yes
│ ├─ wrapper 타입 → JpaMetamodelEntityInformation
│ │ └─ isNew() 판단:
│ │ ├─ version != null → 기존 엔티티 (merge)
│ │ └─ version == null → id == null ? 새 엔티티 (persist) : 기존 엔티티
│ │
│ └─ primitive 타입 → AbstractEntityInformation
│ └─ isNew() 판단:
│ └─ id == null → 새 엔티티 (persist)
│ └─ id != null → 기존 엔티티 (merge)
│
└─ @Version 없음 → AbstractEntityInformation
왜 @version으로 새 엔티티를 판단하는가?
일반적으로 version은 낙관락 사용 시 충돌의 근거를 가지는 필드이다.
즉, version 값이 null이라는 의미는 db에 존재하지 않는 것을 의미한다.
만일 ID 만으로 판단할 수 없는 상황이라면 version이 중요한 역할을 수행하게 된다.
위에서 @version 필드가 존재하고 primitive 타입인 경우 id로 판단하는걸 확인할 수 있다.
@version이 판단에 중요한 역할을 한다고 해놓고, id로 판단하는건 왜일까?
Long, Integer의 경우 null을 가질 수 있고, null이라면 확실하게 새로운 객체임이 증명되는 상황
그렇다면 0이라면 새로운 객체로 판단하면 되는 거 아닌가?
- 새 엔티티 생성
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Version
private int version; // primitive → 초기값 0
}
Member m = new Member();
m.setId(null); // AutoIncrement라서 아직 DB에 없음
em.persist(m);
- 기존 엔티티 조회 후 버전이 0인 경우
Member existing = em.find(Member.class, 1L); // id=1
System.out.println(existing.getVersion()); // 출력: 0
이미 DB에 존재하는 엔티티인데 Version 값이 0일 수 있다.
이렇게 되었을 때, update()가 동작하지 않고 insert()가 동작하게 되는 상황이 발생할 수 있다.
직접 ID를 할당하는 경우
그렇다면 키 생성 전략을 사용하지 않고 직접 ID를 할당하는 경우
├─ @Version 존재? ── Yes
│ ├─ wrapper 타입 → JpaMetamodelEntityInformation
│ │ └─ isNew() 판단:
│ │ ├─ version != null → 기존 엔티티 (merge)
│ │ └─ version == null → id == null ? 새 엔티티 (persist) : 기존 엔티티
│ │
│ └─ primitive 타입 → AbstractEntityInformation
│ └─ isNew() 판단:
│ └─ id == null → 새 엔티티 (persist)
│ └─ id != null → 기존 엔티티 (merge)
│
└─ @Version 없음 → AbstractEntityInformation
│ └─ isNew() 판단:
│ └─ id == null → 새 엔티티 (persist)
│ └─ id != null → 기존 엔티티 (merge)
항상 id가 null이 아닌 상황이고, 새 엔티티라는 판단을 할 수 없게된다.
그렇게 되면 merge가 수행되고 select를 수행한 이후 새로운 엔티티라는 것을 판단하고 insert가 동작하며 성능 손해를 보게된다.
이 때는 엔티티에서 Persistable 인터페이스를 구현하여 직접 isNew()를 구현해야한다.
@Entity
public class Member implements Persistable<String> {
@Id
private String id;
@Transient
private boolean isNew = true;
@Override
public String getId() { return id; }
@Override
public boolean isNew() { return isNew; }
public void markNotNew() { this.isNew = false; }
}
새로운 Entity인지 판단하는게 왜 중요한가?
결국 save() 내부는
insert 할 것인가? update 할 것인가?를 결정한다.
만약 ID를 직접 지정해주는 경우에는 신규 entity라고 판단하지 않기 때문에 merge를 수행합니다.
이때 해당 entity는 신규임에도 불구하고 DB를 조회하기 때문에 비효율적이다. 따라서, 새로운 entity인지 판단하는 것은 중요한 부분이다.
정리
엔티티 저장
- Id 전략 사용
- id == null -> insert()
- Id 전략 미사용
- id != null 개발자가 직접 지정 -> insert() 할지 update()할지 제대로 판단을 하지 않으면 update()가 동작하여 불필요한 select가 발생할 수 있음